Last month, the second and final public testnet for Polygon zkEVM went live. Included in that rollout were meaningful improvements to the throughput, latency, and efficiency of the prover.In the first testnet, Polygon’s Hermez team, lead by Jordi Baylina, deliberately throttled performance to prioritize controlled testing of the soundness and correctness of the prover.
For the second testnet, they made it fast. The time to produce a proof for a batch of transactions was reduced to 4 minutes from 10 minutes. And each of those batches is also larger. More throughput, more quickly.In late December, Polygon zkEVM processed and verified more than 15,000 txs in a single day—more than 5x the one-day high of the first testnet. All within a public, verifiable testnet, with source-available code. More than 60,000 wallet addresses can deploy the smart contracts for generating and verifying Zero Knowledge (ZK) proofs.
This is not a demo disc. If you’d like to audit the code, here are the GitHub repos. If you’d like to join the public testnet, here’s how:
Read more: The Three-Step Guide for Using Polygon zkEVM
But if you’re more of an observer, you can check the block explorer for real-time updates.With these upgrades, Polygon zkEVM becomes among the first known practical recursive ZK proving systems. Given that, we wanted to describe both the concepts and implementations that account for these leaps forward. Namely, aggregation, recursion, and batch size improvements.
The Shrink Ray: Recursion + ZK SNARKs
In the first testnet for Polygon zkEVM, there was one proof per batch. In the second testnet, each batch is further aggregated into a single, bite-sized proof. Recursion—or recursive composition—is the technique that allows for one single validity proof to attest to the correctness of other validity proofs.In a ZK environment, recursion generates something that is otherwise rare: An increase in throughput while also reducing latency. In most applications, time and space are usually a tradeoff. So how is this possible?For recursion to be practical, it must satisfy a cryptographic primitive called incrementally verifiable computation. A cryptographic primitive is a building block for a cryptographic protocol. Which is to say, a building block is only as useful as its application.The goal of a ZK-powered scaling solution is to minimize on-chain data and the cost-intensive computational effort required to validate it. Incrementally verifiable computation is valuable when deployed with ZK SNARK proofs, because ZK SNARKs are shrink rays. They are by nature succinct.
Read more: A Gentle Introduction to Zero Knowledge Proofs
These primitives aren’t novel, and many of the performance gains by the Polygon Hermez team came from Polygon’s Zero and Miden teams. But Polygon zkEVM is the first practical application of them in an EVM-equivalent environment.
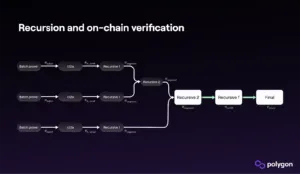
Batches and Aggregation: More is More
To put into context the additional improvements, consider the following: Fitting recursive SNARKs into a practical Zero Knowledge proving system is most easily achieved by using expensive, pairing-friendly elliptic curves. Primarily because this maximizes the cost-savings of SNARKs. However, the elliptic curves that are most efficient for recursion are limited in one important way: They aren’t natively supported by Ethereum.
The guiding design principle for Polygon zkEVM was fidelity to Ethereum and bytecode-compatibility, not the lowest theoretical tx cost. This is why the additional optimizations and upgrades are meaningful. They allow for greater efficiencies without compromising on the broader goal of EVM-equivalence. The first of these upgrades is batch size. The amount of gas throughput that can fit within a batch of transactions is now 150% larger. This is the result of optimizations made to the zkROM, where the instructions for the zkProver and its sub-stacks are stored.
In the architecture of Polygon zkEVM, you can think of batches as boxes moving down a conveyor belt. Each of those boxes contains many txs and they are headed to the prover. But if there is only one prover, there is the potential for a bottleneck. That’s why Polygon zkEVM now supports multiple provers. And so in addition to txs, each batch also contains the hash of the batch ahead of it. With multiple provers working in parallel, the system is capable of proof generation for any segment of the batch chain.
These larger batches are also being aggregated. Specifically, aggregation is the technique that allows one valid proof to attest to the correctness of another proof. Because recursion loosens the gas constraints of proof size by making proofs small, aggregation and recursion are techniques that operate in tandem. The result of recursion and aggregation is that each batch is proofed many times.
But the shrink ray powers of SNARKs aren’t always needed. And so, for the first proof, Polygon zkEVM uses a STARK proof. STARKs differ from SNARKs in several ways, but for the purposes of its implementation here, STARK proofs are faster. This approach optimizes for speed when generating the initial proofs, while the subsequent recursive SNARK proofs optimize for size. Taken together, these efficiencies add up. While the cost per tx today is already less than $0.04, researchers at Polygon Hermez expect the live-rounds environment of the public testnet will help identify ways to reduce that even further.
What’s Next?
Well, Ethereum’s Mainnet. The expected rollout of Q1 2023 hasn’t changed. But first we’ll have the results of the security audit—two independent security teams continue to review and stress-test the source code—along with important news about the security protocols that will be in place when it ships.For the latest, be sure to check the Polygon blog and tune in to our social channels for everything in the Polygon ecosystem. And if you’re interested in (or perplexed by) Zero Knowledge, follow Polygon’s dedicated ZK handle, @0xPolygonZK, and head over to our ZK forum.
Website | Twitter | Developer Twitter | Telegram | Reddit | Discord | Instagram | Facebook | LinkedIn




.webp)

.png)